SoftHebb: The Softmax Variant Behind Backprop-Free Learning
Backpropagation is the backbone behind practically all modern deep learning-based systems. It's the algorithm used to train neural networks which are famously biologically inspired, but also biologically implausible. Our human brains do not learn using backprop. There are many alternatives to backprop and one of them is called Hebbian learning. In this post I want to focus on one aspect of Hebbian learning: a variant of the softmax equation.
The softmax equation is something that comes up again and again in ML. It takes as input a vector of numbers and transforms them into values that sum up to one and can be interpreted as probabilities.
Standard Softmax Equation
It's commonly used in classification tasks where the raw outputs (AKA logits) of a neural network are transformed by the softmax and the value (class) with the highest probability is selected.
Meanwhile in Hebbian learning (and neuro-inspired ML in general), there's a concept known as Winner-Takes-All (WTA). How do these connect to softmax? First, let's define some terms.
What does Hebbian mean?
Donald Hebb was a psychologist from the 20th century who is best known for introducing Hebbian theory.
One of the central ideas of Hebbian theory can best be summed up by this quote: "neurons that fire together, wire together." The idea being that neurons in the brain that activate strongly together are ones whose connections are strengthened.
When you take this idea and apply it to neural networks and machine learning, you get a learning mechanism known as Hebbian learning that is more biologically plausible than backpropagation. For any given pair of neurons, learning takes place locally rather than requiring a full forward and backward pass through the network.
There's much more to Hebbian theory but that's all we need to know for this post. Now let's talk about what WTA is.
Winner Takes All
Think about the vector that is input to a softmax function. It is just a list of numbers. If you keep the largest number (i.e., the arg max), and suppress the rest (i.e., change to 0) then that is essentially all that WTA does. It doesn't have to be the arg max either, it can also be something more akin to top k, where you take the k largest values and keep them while suppressing the rest. So WTA can be thought of as any type of filtering (such as arg max and top k) where there is some kind of competition between the vector's values.

Let's put this together with the original softmax equation.
Modified Softmax — SoftHebb
In Hebbian learning a modified softmax known as SoftHebb is used to better mimic the behavior of the human brain. Competition suppresses weakly activated neurons while strengthening strongly connected ones.
When you combine SoftHebb with weight-update rules then you get a learning mechanism based on competition. Supervision is no longer required so error-based learning (i.e., backpropagation) can be removed. Let's take a look at the modified softmax equation.
SoftHebb Equation
So why are there 2 equations? They're both equivalent actually, the only difference is one uses a b term called gain and the other uses a τ term called temperature. The τ version looks similar to the original equation, it is nearly identical except for the temperature divisor. The temperature term itself might also sound familiar, it's everywhere in modern ML. When you want more randomness in LLM outputs you crank up the temperature. Its usage in controlling LLM output is the same here: higher temperature = outputs are closer to each other (less spikiness).
Just to drive home how b and τ are equivalent, the relationship between the two is:
So this matches: when
In Hebbian Learning the gain terminology comes up a lot because:
- In biologically-inspired models, people think in terms of gain and amplification.
- Thinking about gain in terms of a limit becomes more intuitive.
As gain goes towards infinity then the SoftHebb values sharpen and a WTA "regime" takes hold. When gain goes toward 1 then it diffuses the output distribution of SoftHebb and everything becomes more even.
As for the weight-update rule, the WTA-like output of SoftHebb tells you which neuron "won" and a local Hebbian update strengthens just that neuron's input weights. No global error signal required.
Check out the below visualization to see how manipulating the gain changes the spikiness of SoftHebb's output. If you keep gain equal to e, then the equation is identical to the original softmax equation.
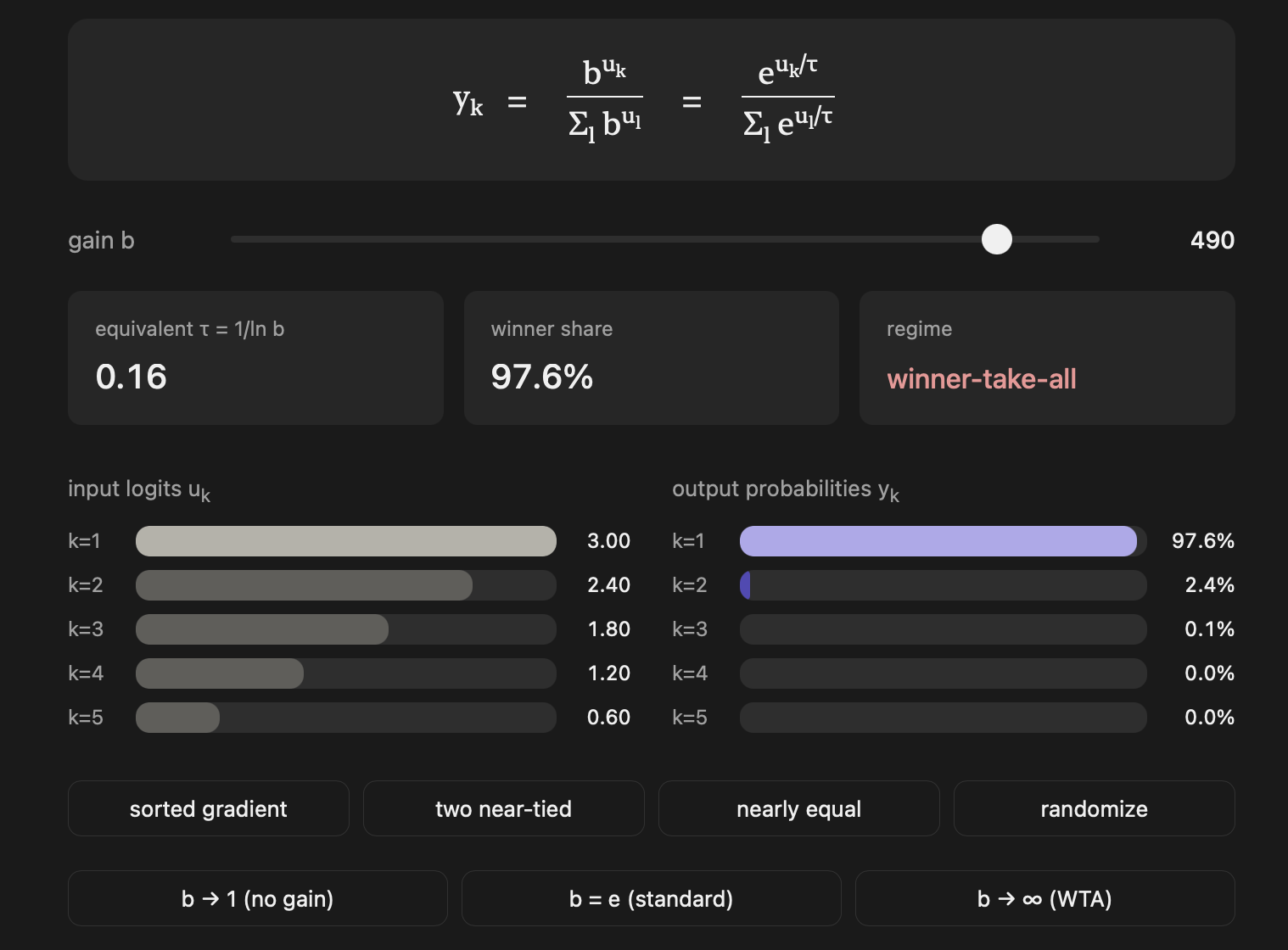
Open the interactive Softmax Gain Explorer
Try playing with the widget to see when the WTA regime takes hold.
Better Than Backprop?
Hebbian learning is a super interesting, biologically plausible alternative to backprop. But is it actually better? One paper found that Hebbian learning did outperform other backprop alternatives like Predictive Coding and Direct Feedback Alignment, but it did not beat deep neural networks. SoftHebb has been shown to work in relatively shallow deep networks, but not yet at the depth and scale of modern backprop-trained models. A likely challenge is that purely local Hebbian signal become harder to coordinate across many layers.
If you found this helpful or if you're interested in backprop alternatives, feel free to get in touch. And if you're interested in this topic I recommend reading Geoffrey Hinton's Forward-Forward paper, another backprop-free way to train neural networks that coincidentally came out around the same time as Hebbian Deep Learning Without Feedback.